
“Any sufficiently advanced technology is indistinguishable from magic” - Arthur C. Clarke
Today I’d like to talk about LLMs. But first, I’d like to talk about an impressive invention from the late 1700s.
The Mechanical Turk
The Mechanical Turk - or “The Turk” as people called it - was an autonomous chess-playing machine. Built in 1770, it went on tour across parts of the world for 84 years as a robot playing chess against human opponents.

A Drawing of the Mechanical Turk
People would stand in line for a chance to view the Turk at exhibitions. A select few were chosen to play against it. Players were always informed that The Turk would use the white pieces. In 1809, Napoleon I of France played against the machine. According to some records, the Turk went so far as to salute him before the match started!
As the popularity grew, so too did the sophistication of the machine. In 1819, some new changes to The Turk debuted:
- It now allowed the opponent to make the first move.
- The king’s bishop’s pawn was eliminated from the Turk’s pieces.
- This “pawn handicap” created further discussion of, and interest in, the Turk.
- It even led to a book being written by W. J. Hunneman chronicling the matches played with this disadvantage.
Despite the “pawn handicap”, when all was said and done the Turk’s record was 45 wins, 3 losses, and 2 stalemates. Not bad! Sadly, the Turk’s chess-playing career was ended when it was destroyed in a fire.
Many books and articles were written during the Turk’s life about how it worked. Most were inaccurate, drawing incorrect inferences from external observations - because people didn’t know or understand how it actually worked.
The Turk Was a Fraud
The Turk was a lie. It was never an automaton. It was always a sophisticated illusion. The design of the machine was such that it convinced people that it was not possible to hide a person within the machine. After all, part of the exhibition was opening all of the front cabinets and drawers to “prove” that no one was inside!
But after its demise, it was finally revealed that a human chess master hid inside the machine, operating it with a simple candle for light and a series of sophisticated levers. A truly ingenious device, especially given the period in which it existed.

A Cross-Section Drawing of the Mechanical Turk
Magical Thinking
As with the Turk, a lack of understanding can create a sense of wonder, mystery, or even supernatural influence. We see this often in children who are developing their understanding of the world. We also see this in situations where complex technology is not fully grasped. Rather than apply a scientific eye and critical thinking, people instead choose to embrace the fantasy of possibility.
Arguably no real “harm” was done by believing in The Turk, as it was a spectacle for amusement, so perhaps people going along with the ruse was harmless. But today, a $100 billion dollar ruse is operating and unfolding right in front of us: LLMs (often referred to as “AI”).
Just like the era when the Turk captivated audiences, today people are writing feverishly and constantly about LLMs. And just like the stuff written about the Turk, most articles on LLMs are inaccurate, drawing incorrect inferences from external observations - because people don’t know or understand how they actually work.
With this blog post, I aim to teach you exactly (at a very high level) how LLMs actually work. My only goal is to empower you with knowledge that you can use to draw better conclusions and make better decisions. So let’s dive in.
LLMs Today
Today, every social media site, blog, and tech-adjacent news site or subreddit thread seems to be talking 24/7 about LLMs. This is not surprising when you consider how many billions of dollars investors are pumping into AI startups.
“In under three years, AI has come to dominate global tech spending in ways researchers are just starting to quantify. In 2024, for example, AI companies nabbed 45 percent of all US venture capital tech investments, up from only nine percent in 2022.” (source)
They are currently an ever-present part of our lives, with many major companies trying to force the latest models into our collective lives via forced updates of software and hardware that we never really owned in the first place. My Android phone is now slathered in Gemini whether I like it or not, and I am sure Apple is doing similarly with iOS. Every time I go to LinkedIn they offer a premium feature where an LLM writes my posts for me (gross). And I don’t even need to detail how people use LLMs to constantly generate images of Miyazaki people doing things, often with 1 finger too few or too many (which is quite frankly hilarious).
LLMs are EVERYWHERE.
LLMs Are Grossly Misunderstood
I see a lot of people talking about how they have “tuned” an LLM to their writing style, ways of thinking, or even to be their pal. How the LLM has “learned” to communicate more effectively with them from their writing. And of course, naturally, how the LLMs are going to take all of the Junior level jobs - especially in the field of programming!
But it’s clear to me that most people don’t understand how LLMs actually work. So let’s walk through it together. Buckle up.
0. LLMs Are Advanced Neural Networks
Neural networks are complicated. They’ve been around for a long time - well before the rise of LLMs. The simplest way I can think of to explain them is to use an analogy of walls of doors:
- Imagine you are standing in front of a wall of 100 doors. You can only go through 1 of these doors.
- The door you go through is based on the first word of the last sentence you said or wrote.
- This door leads to only SOME of the next row of doors being available for you to open (your choices have blocked off some paths).
- Once you open the next door based on the second word of that sentence, the NEXT layer behind it reveals itself, again with only a subset of the doors available for you to open based on the doors you opened previously.
- Eventually you progress through all of the walls of doors and end up at a destination.
- Doing all of this takes some non-trivial amount of time, perhaps 10 seconds.
In this analogy, the walls are the neural network layers and the doors are the neurons. In a classic neural network, a neuron is a graph node that receives input (from the prior layer that led to it) and generates output (the path to the next layer). Each neuron layer usually only connects to the layers immediately preceding and following it. The first layer is usually the “input” point, and the last layer is typically the “output” result.
One of the most successful and earliest examples of a Machine Learning Neural Network is the online implementation of the classic kids game “20 Questions”. It’s hosted on an old site at http://www.20q.net - feel free to play a round or two (if you feel like ignoring the scary HTTP insecure site errors)!

A Diagram Depicting A Neural Network
LLMs are a special kind of advanced neural network. They combine the concepts of a traditional “feed-forward” neural network with bleeding-edge techniques such as “self-attention” and “attention heads”. LLMs define their depth with parameters rather than neurons and layers. These are not neurons, and they don’t map in a 1:1 fashion. Each parameter represents a trained set of weights and biases that make up the overall model behavior. To give you an idea of how large these LLM networks are, they often have 200 or even 500 billion parameters - and sometimes even more. They are MASSIVE.
1. LLMs Don’t Understand English (or other languages)
This is confusing right? You type English, and it sends English back, so how can it possibly not understand English?
You can say the same as above for any other language too.
LLMs don’t speak in the languages we do; they only speak in tokens. And tokens are created by tokenizers.
When you type something to your favorite LLM, it will first tokenize what you wrote. This process breaks your sentence into multiple tokens, which are the true “language” that LLMs speak. Classic tokenizers will tokenize sentences into individual words based on white space and punctuation. For example, if we sent this sentence:
It was the best of times, it was the worst
A whitespace tokenizer might produce:
['It', 'was', 'the', 'best', 'of', 'times', 'it', 'was', 'the', 'worst']
However, LLMs do not operate on character or string tokens. For performance and memory efficiency reasons, they operate on numbers (the “bare metal” data format of computers). LLMs use number tokens, with a unique number assigned for each unique token.
GPT-4 uses a Byte Pair Encoding (BPE) tokenizer called cl100k_base. This tokenizer processes text sequentially to produce numeric tokens based on a machine learning heuristic. ck100k_base would tokenize our sentence as:
[2181, 574, 279, 1888, 315, 3115, 11, 433, 574, 279, 12047]
The total set of tokens known and defined by an LLM constitute its vocabulary. It works just like your vocabulary: you know the words you know, and you don’t know the words you don’t. Same for the LLM. It can only understand and reply to tokens it has in its vocabulary.
2. LLMs Are Immutable (Read-Only)
LLMs are “frozen in time” with the knowledge they were trained on. They do not learn. They feel like they learn, because they employ some tricks used to better pattern-match how you write or talk, but they are in fact read-only and not learning anything from your inputs.
This creates a few interesting challenges:
- An LLM last updated on March 1, 2025 will have no knowledge of news or events that have happened after that date.
- We can’t just insert new facts, because the neural network generated by LLM training is incredibly tightly-coupled and interdependent, weighted and trained very carefully, and actually quite fragile. Adding something new might drastically change the model’s behavior.
- Therefore a new model must be released every so often, trained on the latest data, so that the LLM can respond to current events and stay “up to date”.
- Training models is very expensive and time consuming.
- Because the model consists of billions of neurons which have numeric values and connect in multiple ways to each other, there is no way to cite sources of data or provide reliable attribution. This is because results are “synthetically generated” as the sum of multiple original sources, and those sources are not included directly in the embeddings.
Additionally, even if you could open an LLM up to learning from prompts, you probably don’t want to. As Microsoft learned back in the 2010s with the launch of a bot named Tay on Twitter, letting people on the Internet actively train your bot is usually a bad idea . So these things are also read-only so that no one runs into these problems.
The companies creating LLMs are smart. They have figured out some clever workarounds for the limitation of things being read-only.
RAG
One such workaround is what’s known as RAG or Retrieval-Augmented Generation . This was one of the earliest “hacks” everyone figured out, and it’s pretty useful. Essentially you send the LLM the data you want it to use, and ask it to summarize that data. And it will be able to do so assuming the data that you sent it exists within its vocabulary which it typically will (how often do we really invent new words in language?). This data can be from a source that’s more recent than the model’s read-only state (such as a blog post written today).
This approach is very useful for things like Google’s Gemini working off of search results. Essentially Google will retrieve the results for your search, then send Gemini a prompt that contains content from these results and ask it to summarize things for you.
A very naive example (for learning purposes) would be as follows:
You search “how to get rid of groundhogs in my yard” (as I recently did, because I have one, and it’s a nuisance!)
Google finds the results for that query, just like it used to before LLMs were a thing
Google takes the CONTENT of the top n results (say 3 or 5), and generates a prompt for Gemini
The prompt is essentially (crudely, for learning purposes):
given the context of X (the content from the top 3 or 5 results), summarize it in at most 5 paragraphs of no more than 4 sentences each. For each paragraph, cite the website as the source of your statement. Phrase your response as an answer to this statement: “how to get rid of groundhogs in my yard”
Gemini spits out some LLM content in response, and Google displays it to you above the search results
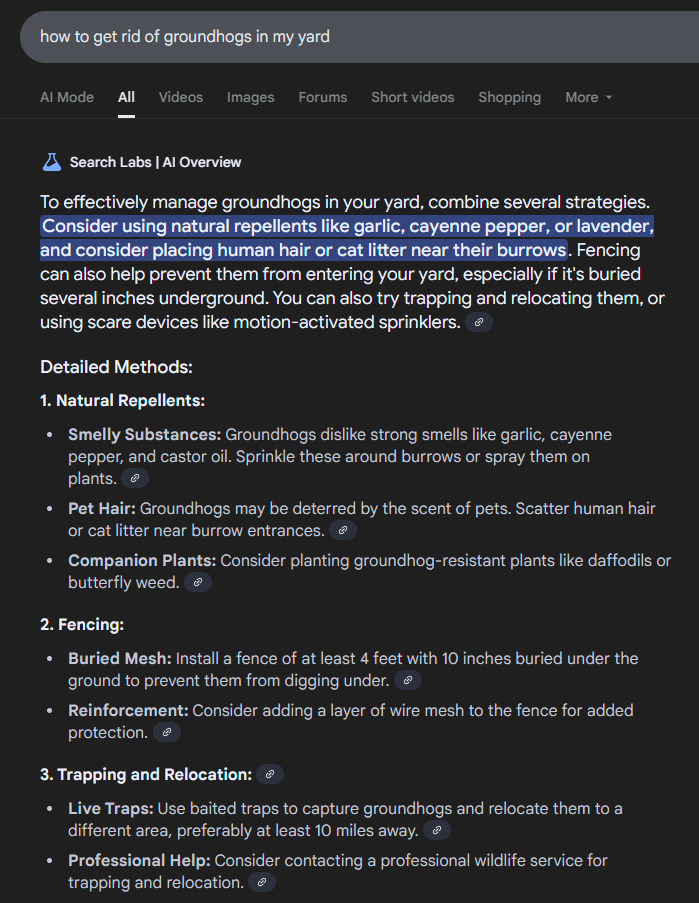
An Example Gemini Response for Google Search
Long Prompts As Context
Ever noticed how when you ask an LLM a question, it gives you a (usually detailed) answer, but then if you ask a follow-up without providing context, it will still know what you’re talking about and the conversation will flow naturally?
For example, ask it to write you a rhyming poem about cats. And then when it does, simply respond with “try again and make it funnier” (note the total lack of context defining “it”). And it’ll do it again!
If the LLM only considered each prompt you sent it by itself, it would have no idea what “it” was and would hallucinate wildly (or tell you it doesn’t know, depending on how it has been trained).
What typically happens now is that whenever you send a prompt, the LLM front-end app will actually send a bunch of your most recent prompts and sometimes its prior answers ahead of your next prompt, to provide context. This allows the conversation to flow “naturally” and for you to feel like you’re talking to intelligence. This is also why you’ll get told that you’ve run out of space for a given conversation with an LLM, and need to start a new session or conversation. With all that context, you’ll eventually hit the token limits.
This is the method by which people “tune” their LLMs. But as we discussed prior, the LLM doesn’t actually learn anything. It’s a parlor trick - though a convincing and often useful one.
3. LLMs Don’t Understand, They Just Guess
Fundamentally, all LLMs do is just pattern match. They use sophisticated algorithms to do so (and this involves more advanced methods of tokenization). But the high-level process is:
- The LLM converts your prompt into numeric tokens.
- It walks the giant LLM Neural Network with these tokens, in order, because order matters in language meaning.
- When it reaches the end of your prompt, it continues down the network by guessing the next sequential tokens using heuristics based on training data.
- The training data is typically the corpus of the entire public Internet, plus many copyrighted and even pirated works.
- Fun fact: the large number of formally written documents (which use em-dashes) used to train LLMs are why they often prefer to use em-dashes in generated text!
- It uses a decoder-only transformer to return these “guessed” numeric tokens back to conversational language (usually in whatever language you’re communicating in).
- It returns that human-readable language back to you.
Confused? Let’s use a simple example. Say you give an LLM this sentence as your prompt:
The sky is
The LLM will turn that into numeric tokens, walk the graph of parameters, and then guess at the next parameters past your prompt to “complete” the statement.
The response could start with:
blue(what most people would guess and thus have written in training data)grey(orgray) because sometimes it’s cloudy and rainy, and because we spell it differently in different parts of the worldabove uswhich is also true for most peoplea movie made in 2020which has probably also been written about
The LLM can respond with any of these answers, or many others that you aren’t expecting as well. The most extreme of these “off-base” answers are what we call hallucinations.
Hallucinations are when the LLM, when guessing what comes next from its enormous amount of training data, gets it very “wrong” with respect to what you expected (because it lacks understanding), and then goes down a “path” in the neural network that seems nonsensical and completely off-topic.
As for how it picks what words and sentences come next for your prompt…
4. LLMs Are Random By Design
Ever talked to a “dumb” robot that only answers yes and no? It gets pretty old, pretty fast. The novelty wears off real quick.
Going beyond binary bots, think of the Magic 8-Ball toy and its finite set of a dozen-ish answers. It’s random, it varies, but it’s not THAT random and so the novelty quickly fades. Outlook not so good.
What if you talked to an LLM and it always gave you the exact same answer for the exact same question? That would be pretty boring too. It also wouldn’t feel smart, human, or conversational. You’d probably think “yeah this is definitely a bot”.
But the LLM creators don’t want you to see it for what it is: a bot with a sophisticated “guess the next words from the training data” algorithm.
They want you to see it as a thinking, feeling, learning, reasoning, problem-solving, decision-making solutions to all of your problems.
As a result, most LLMs implement a variable called temperature which usually ranges in value from 0 to 1. This variable defines how random the LLM replies are, balancing predictability with creativity (which is the key to making the whole thing feel like an actual thinking AI). A value of 0 will be almost fully deterministic - giving the exact same answer to the same question every time. A value of 1 will make it almost completely random, making the odds of you getting the same answer (or even a similar answer) much lower (but possible, because again it’s random).
The key mechanic to making LLMs feel human and smart is randomness. They are semi-random by design.
This becomes more fascinating the more you think about it, because it has serious implications - especially around work.
LLMs Aren’t Replacing People
Right now businesses are trying (and failing) to use LLMs to cut staff and save money by automating work:
- A Fortune article from May 18th 2025 reveals that a study looking at AI chatbots in 7,000 workplaces finds ‘no significant impact on earnings or recorded hours in any occupation’
- Klarna was perhaps the poster-child for experimenting with downsizing staff in favor of LLMs. It took less than 2 years for Klarna to regret this decision: Company Regrets Replacing All Those Pesky Human Workers With AI, Just Wants Its Humans Back, “What you end up having is lower quality.”
No businesses are seeing measurable revenue gains from LLMs, and the ones trying to replace people are failing and walking it back.
Why? If you’ve read this far, you already know the answers:
- LLMs are read-only (frozen in time).
- LLMs are random by design, and most business processes should not be random (especially programming and money stuff).
- LLMs don’t understand English (or any other human language).
- LLMs do not think, and are not capable of reasoning or logic.
- LLMs also don’t understand math (which is very important in both programming and business processes).
What About Copilot, Claude, and Cursor?
Spoken languages are non-deterministic. Coding languages are both Turing-complete and deterministic.
You can think of your favorite coding LLM as a “non-deterministic transpiler” that uses a guessing heuristic and a configurable level of randomness to generate some deterministic code.
But as logic dictates, a non-deterministic system cannot generate a deterministic result.
Non-deterministic systems are characterized by unpredictability and inherent randomness, meaning that the same input can lead to different outputs. Determinism, on the other hand, implies a system where the output is entirely determined by the input, with no room for chance or variation.
Humans aren’t always deterministic, but we have the ability to learn and reason. LLMs don’t. That’s why we can fix their code but they can’t reliably fix ours.
As developers, what we’re actually paid for is NOT our ability to generate code. It’s our ability to reason, learn, think critically, understand the context of the code around the code we’re writing, and to solve business problems as well as make presentations, draw diagrams, and present to others. LLMs can do NONE of that reliably.
If your next argument is “well we just need a few humans in the loop to supervise the outputs of the coding LLMs” then I say to you: sure. And what do those humans need to know? All the stuff I wrote above, making programmers still important and valuable in organizations even if this unfortunate future were to occur.
What About Agentic Systems?
After a bit of experimentation and due diligence, businesses generally discover that a single LLM cannot reliably solve their automation or process problems. Enter Agentic Systems - systems of LLMs with software overseeing and orchestrating things and adding tools to try and produce better results!
Agentic Systems are basically just management and oversight software that attempt to orchestrate multiple LLMs at the same time with other tools in intelligent and cohesive ways. They take a prompt, talk to LLM A, then feed those results into B with some enriched external context for more results, and then pass that to a bash shell to execute a command, and so on - to create a “tool chain” that does what you want by automating a process for you.
Do they work? Sure, for some definition of “work”. But fundamentally, these Agentic Systems still use LLMs which are random by design and non-deterministic, and so any results you get from an Agentic System will be… random and non-deterministic!
LLMs Are Mechanical Turks
Here’s the dirty little secret that no one wants you to know: these LLMs, when freshly trained on data, have such complicated neural networks that no one can test every possible output path. And because there are billions and billions of paths, there are probably a few that are problematic or not ideal. As LLMs have no real concept of bad and good topics (again they do not reason or understand language), they can sometimes produce very harmful outputs (like telling someone to harm themselves, or providing the recipe for home-made napalm).
The way they are made “good” is by a final “polishing” step in the training process which is called RLHF (Reinforcement Learning from Human Feedback). This process employs tens of thousands of people, often in off-shore countries, typically for a meager dollar rate (I heard $15 an hour once) to use their human brains and reasoning and critical thinking skills to “polish” the outputs of the LLM. The RLHF tuner will look at outputs that are not desired (like recipes for napalm) and reinforce learning manually back into the LLM to teach it never to pick that route through the neural network again.
In the same way that the Mechanical Turk had a human thinking and doing things under the guise of an automaton, LLMs have many thousands of humans fine-tuning the end results to be “safe” and “socially responsible”.
And this is a never-ending cat-and-mouse game. Smart hackers find new and exciting ways to “jailbreak” the finely-tuned safeguards of an LLM, and then the RLHF crew patches that exploit, then the hackers find another one, and they patch that, and on and on the dance goes forever.
Like the Turk, the secret ingredient is people.
Read About Model Collapse
Model Collapse is a complicated and important topic in the world of machine learning. It’s especially important in the context of LLMs.
When OpenAI released ChatGPT 3 in late 2022, it was revolutionary. This was partially because nothing like it had ever hit the mainstream before. This was also because OpenAI had used a large part of the Internet to train the model, and up until that time, the Internet mostly consisted of human-written articles, blogs, and forum posts. So the quality and quantity of training data was exceptional.
Have you noticed that almost all of the new models released since then have been underwhelming, offering diminishing returns?
Training an LLM is a lossy process, where data is not perfectly mapped 1:1 and some data entropy occurs as a result of the process of tokenization and neural network mapping and generation.
Since that “initial” big release, a lot of people have used LLMs to generate content for things like their websites, social media and forum posts, Reddit, LinkedIn - you name it. And the smart people at the LLM companies realized that training new models on their (or other models’) outputs compounds errors and makes them essentially “dumber”.
The LLM creators had poisoned their well of training data by enabling LLM generated content to saturate the Internet.
To continue to make the progress that investors demand, they realized they needed trustworthy (human-created) data to train on. They tried to solve this in a few ways, but none have proven effective (yet?).
Detecting LLM-Generated Content
The first attempt to solve this problem was to detect content that was generated by LLMs rather than humans. This facade was kept up for about a year before OpenAI finally admitted that no detectors “reliably distinguish between AI-generated and human-generated content.” .
Their source of data (the Internet) was now “polluted” with a significant amount of LLM-generated content, and they had no way to know what to train on and what to disregard and avoid. So now the LLM companies have the problem that training a newer version of their model on the “latest” Internet data means that they are consuming their own outputs, compounding errors and entropy, and making their models dumber.
Synthetic Data
Another approach that LLM companies tried was the concept of Synthetic Data. This is data that is generated as if a human wrote it, for the LLM to train on.
I predict that you’ll hear urgently increasing talk about this idea in the coming months.
Make no illusions: synthetic data doesn’t exist and it isn’t a real thing that we can do.
If it were real, our problems would be solved. The LLMs would just train on suitable synthetic data when creating new models, and they would continue to get smarter (or at least not get dumber).
But it’s not real. Because there are currently only 2 ways to generate training data for LLMs:
- Humans create data for the LLM to consume and train on (this is “good”)
- Machine (like LLMs) generate synthetic data for LLMs to consume (this is “bad” and causes Model Collapse)
Data Partnerships
Some LLM companies are striking deals with popular forums and websites to gain licensed access to their content and data for training purposes. Sites like Reddit and Stack Overflow surely participate in these arrangements, and not-so-coincidentally have adopted “no bot content allowed” policies for users as well. The problem is that, because we cannot detect LLM-generated content, this data is not as valuable or trustworthy as one would like it to be. As a result these partnerships, in my opinion, are most likely ephemeral and little more than wishful thinking.
Prediction: LLMs Will Only Get Dumber
I’m calling it right now, and I pledge to never edit this statement out of this blog post in the future:
Model collapse has begun, and LLMs will only get dumber from this date forward.
Hopefully this will lead to the AI hype bubble finally bursting. But what do I know? Investors continue to pour billions of dollars into AI startups, despite the reality that currently:
- No company has proven that they’re saving money and succeeding by replacing workers with LLMs.
- Even if a company COULD replace developers with LLMs successfully, they will still need skilled developers to oversee and correct the outputs, which necessitates the continuing software developer career path.
- LLM companies like OpenAI are not profitable.
- In 2024, AI companies nabbed 45 percent of all US venture capital tech investments, up from only nine percent in 2022.
- Time and time and time again, experiments in having LLMs write code begin to fail as soon as the code moves beyond basic examples and use cases.
In any case, LLMs are not the path to AGI.
Use Your Head
The set of differences between you and an LLM are vast, but most potently rooted in what makes us human: critical thinking, learning, problem solving, and reasoning skills. I implore you to keep sharpening and building these skills.
Don’t outsource thinking to a system that cannot think, even if the temptation is strong and everybody else seems to be doing it. It might seem easy right now, especially in low-accountability work environments, but you’re only hurting yourself in the long-run.
As the saying goes: “if you don’t use it, you lose it”. If you don’t continuously sharpen your skills, they fade.
And if your only skill at work is making LLMs spit out code or generic emails full of em-dashes, then they actually can (and probably will) replace you.
David Haney is the creator of CodeSession - a platform that helps companies do collaborative coding interviews AND avoid LLM cheating. None of this blog post was written by LLMs.
Thanks to my good friend balpha for his invaluable efforts in proof-reading this post.